AI Explained: Retrieval-Augmented Generation (RAG)
And why it'll become the most popular application of AI across industries

The problems with AI and how RAG solves them
We’ve all encountered these issues when using AI tools like ChatGPT:
- Hallucinations: when AI confidently makes up facts that are so far from reality.
- Outdated Knowledge: ChatGPT’s knowledge cutoff date is January 2022 for GPT 3.5 and April 2023 for GPT-4, meaning you have to wait for OpenAI to keep updating it’s knowledge.
- Too general: ChatGPT’s knowledge is a blend of all the data it was trained on and you need to write detailed prompts and give ample context to get responses that are uniquely relevant to you.
- Privacy: people don’t want to input their proprietary data into AI tools because of privacy concerns (and competitive reasons, of course).
Retrieval-augmented generation, or RAG for short, solves these problems because it allows you to:
- Retrieve information that only exists in your knowledge base, which reduces the likelihood of hallucinations. RAG can also provide specific references to the documents it used to generate a response.
- Easily add new documents with updated knowledge and facts to your knowledge base.
- Not train the AI model on your data, but rather performing searches on the most relevant pieces of information across your documents, and using an LLM to formulate a response.
If this sounds complicated, it’ll make much more sense once I break down the RAG process in more depth, without getting too technical. If you’re interested in the technicalities, read until the end for my favourite free resource on this topic.
The RAG process
Let’s break down the RAG process to understand how it works, but also eliminate some misconceptions that may stem from oversimplifying it:
For the sake of the explanation, let’s say we want to build a chatbot to onboard new employees to a company. This would help new employees:
- Learn about the company’s mission, vision, values, code of conduct, etc.
- Ask questions about HR policies, company perks, health benefits
- Find relevant documentation and training for their role
As the company, we would need to do this:
1. Collect a set of documents that will form the knowledge base for our onboarding chatbot. This could include documents like employee handbooks, a code of conduct, company perks, and a health benefits booklet. They should have a text format, rather than images or videos*.
*It’s possible to use videos as a data source in your knowledge base using frameworks like LangChain. They usually transcribe videos into text and store that as a document, rather than the video itself.

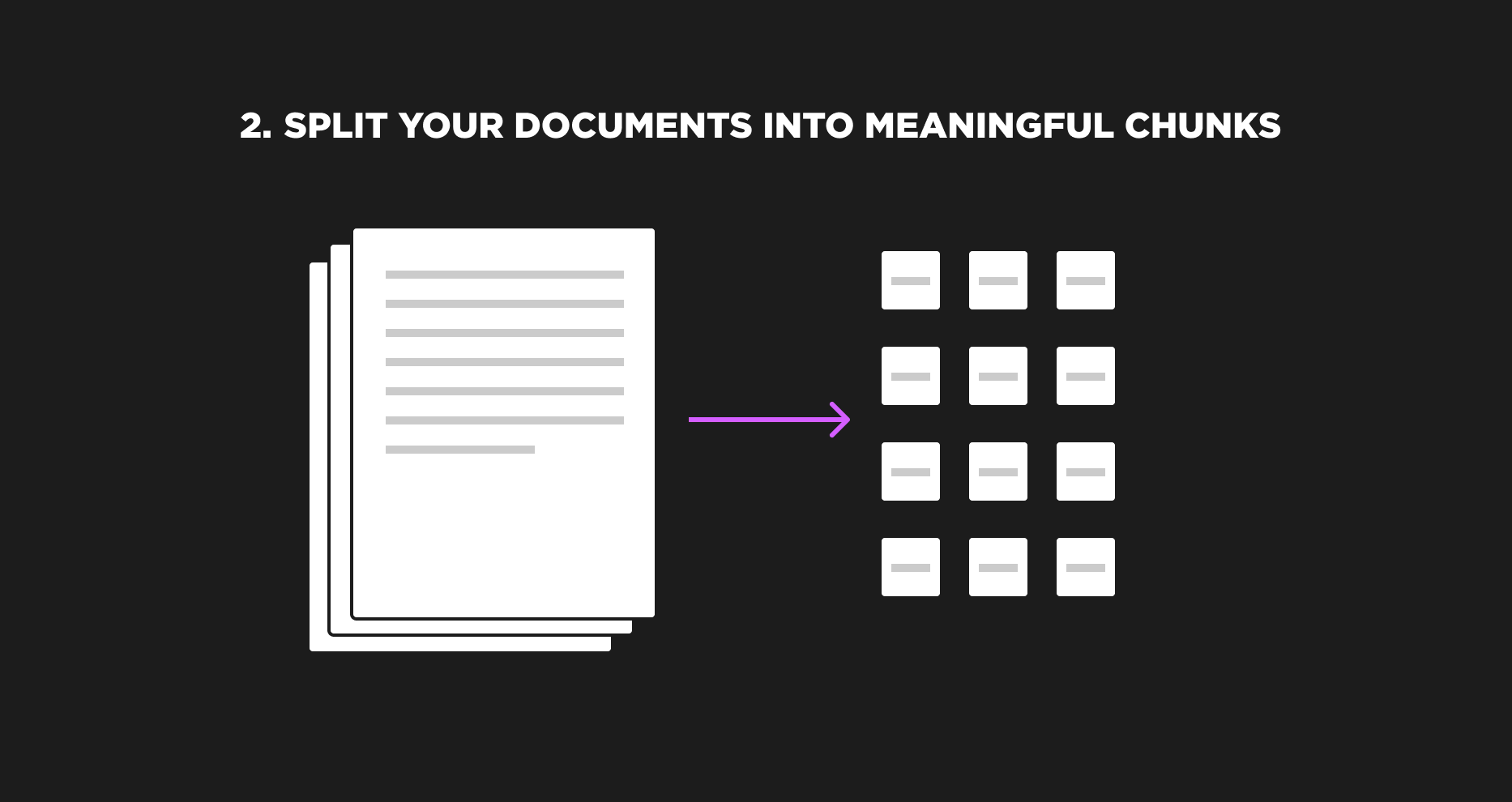
2. Split the documents into semantically meaningful fragments. Imagine this as digitally shredding each document you have. Each shred could have a sentence, paragraph, a certain number of characters, or any split that makes sense to you. This wouldn’t be done manually, instead you would use a framework like LangChain with built-in document splitting capabilities and options.
3. Store that knowledge in a vector database. Each text fragment has a numerical representation, called an embedding.

4. Retrieve the relevant knowledge by searching our vector database. For example, if the new employee asks about dental benefits, your system will perform a similarity search across your vector database to find the most relevant text fragments across all your documents.

5. Generate a response by transforming the retrieved text fragments into a coherent response. This process is usually performed by an out-of-the-box LLM that you can choose (such as GPT-4). You can also return the specific references from the documents in your responses, which can help people fact-check or find more info.

The term “retrieval-augmented generation” should make more sense to you now.
I made this quick illustration to hopefully clarify any confusion:
The potential of RAG
Once you understand RAG, you start understanding the immense possibilities and potential it can bring to so many companies.
Every company has a growing number of documents, data, reports, presentations, spreadsheets, and more.
Frequent documentation, filtering, tagging, and other organizational methods can only take you so far or be done consistently for so long. At some point, your company grows too much, knowledge silos are created and not maintained, and everyone’s scrambling to find the right knowledge across the documentation.
It becomes even worse when experienced employees leave the company, leaving huge knowledge gaps behind them.
With RAG, you could build useful and valuable assistants for specific functions and departments. Some examples:
- An onboarding assistant for new employees to answer questions about policies, benefits, perks, and the company roadmap
- A customer service assistant for customer service agents to quickly find answers while assisting customers
- A coding assistant for developers to answer questions about technical documentation, components, APIs, and debugging
- A design assistant for designers to answer questions about the company’s design system, best practices, UX/CX research findings, usage metrics/analytics and competitive analysis
Ultimately, these assistants create immense productivity gains and allow everyone to leverage a rich knowledge base for their work.
Imagine how many documents are spread out across each organization and how many applications and tools they use regularly…
Now imagine you could connect all these data sources, search them collectively, and get coherent responses in return…
That’s the power of RAG.
Learn RAG for free

The best free resource to get a sense of how RAG works while having fun is DeepLearning.AI’s course LangChain: Chat with Your Data. I did this course last summer (it only takes an hour) and I’ve recommended it to so many people since:
LangChain: Chat with Your Data
